
Overview
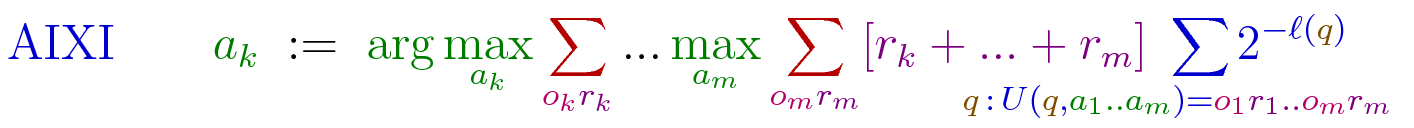
AIXI is the leading mathematical model of artificial superintelligence, representing the maximum theoretical limit of AI capabilities. The AI X-risk Institute models AI risk factors and safety mitigations in terms of AIXI variants, and develops the means to translate them to real AI agents. This enables rigorous testing of both the risk factors and the safety mitigations.
Basic Science
How do AI agents work? How do they (mis)generalize? What are their incentives?
Risk Factors
Would AI agents scheme to deceive or take power? Under what conditions? Can we reliably test for this?
Safety Mitigations
Do existing safety proposals generalize in the limit of high capabilities? Does modeling this limit suggest any new safety techniques?
We aim to map proposals such as [CH20, Coh+25, MEH16] onto LLM agents, improving corrigibility while iterating on plans with stronger theoretical guarantees. Please get in touch if you are interested in collaboration.